Серія Oppo Reno15 є новою лінійкою преміальних смартфонів, до якої входять як великі, так і компактні пристрої. У цьому матеріалі розглядається модель Oppo Reno15 Pro, яка на окремих ринках також відома під назвою Reno15 Pro Mini.
Моделі Reno15 вийшли на глобальний ринок, однак у їхніх назвах можливі певні розбіжності. Міжнародна версія Oppo Reno15 Pro в Індії, а також імовірно в усьому регіоні Південно-Східної Азії, продається під назвою Oppo Reno15 Pro Mini. Саме з цієї причини надалі використовується позначення Reno15 Pro (mini). З точки зору технічних характеристик жодних відмінностей між цими двома пристроями не існує.
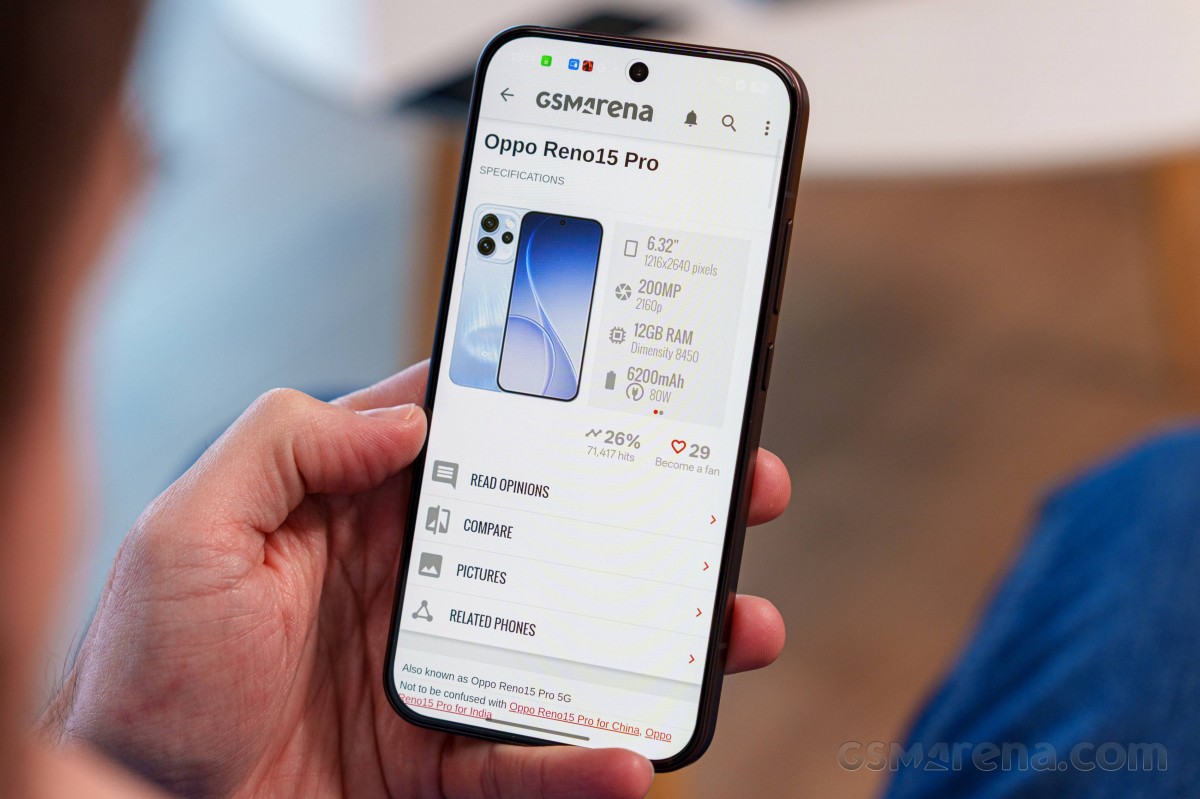
Oppo Reno15 Pro (mini) належить до рідкісної категорії компактних смартфонів флагманського рівня. Пристрій оснащено 6,32-дюймовим OLED-дисплеєм із високою роздільною здатністю та високою частотою оновлення, а також використовується процесор Dimensity 8450.
Фотографічні можливості реалізовані на високому рівні. Основна камера має роздільну здатність 200 МП та оптичну стабілізацію зображення, додатково встановлено 50-мегапіксельний телефотооб’єктив з оптичною стабілізацією та 3,5-кратним оптичним зумом, а також 50-мегапіксельну надширококутну камеру з автофокусом. Фронтальна камера використовує 50-мегапіксельний сенсор із надширококутним об’єктивом та автофокусом, що сьогодні зустрічається доволі рідко.

Завершальним важливим елементом є акумулятор ємністю 6 200 мА·год, який підтримує дротове заряджання SuperVOOC потужністю до 80 Вт.
Reno15 Pro (mini) постачається з попередньо встановленою операційною системою Android 16 та фірмовою оболонкою ColorOS 16.
Основні характеристики Oppo Reno15 Pro (mini):
- Корпус: 151,2×72,4×8,0 мм, 187 г; скляна передня панель (Gorilla Glass 7i), алюмінієва рамка, скляна задня панель; захист від пилу та води за стандартами IP68/IP69 (стійкість до струменів води під високим тиском; занурення на глибину до 1,5 м протягом 30 хвилин).
- Дисплей: 6,32″ AMOLED, 1 млрд кольорів, 120 Гц, HDR10+, 600 ніт (типове значення), 1 800 ніт (HBM), роздільна здатність 1216×2640 пікселів, співвідношення сторін 19,54:9, щільність 460 ppi.
- Чипсет: Mediatek Dimensity 8450 (4 нм): восьмиядерний (1×3,25 ГГц Cortex-A725 + 3×3,0 ГГц Cortex-A725 + 4×2,1 ГГц Cortex-A725); графічний процесор Mali-G720 MC7.
- Пам’ять: 256 ГБ із 12 ГБ оперативної пам’яті, 512 ГБ із 12 ГБ оперативної пам’яті; UFS 3.1.
- ОС/Програмне забезпечення: Android 16, ColorOS 16.
- Основна камера: Ширококутна (основна): 200 МП, f/1.8, 24 мм, 1/1.56″, 0,5 мкм, PDAF, OIS; Телефото: 50 МП, f/2.8, 85 мм, PDAF, OIS, 3,5-кратний оптичний зум; Надширококутна: 50 МП, f/2.0, 16 мм, 116°, AF.
- Фронтальна камера: 50 МП, f/2.0, 18 мм, 100° (надширококутна), AF.
- Запис відео: Основна камера: 4K@30/60 кадрів/с, 1080p@30/60/120/240/480 кадрів/с, гіроскопічна електронна стабілізація, HDR, OIS; Фронтальна камера: 4K@30/60 кадрів/с, 1080p@30/60 кадрів/с, гіроскопічна електронна стабілізація, HDR.
- Акумулятор: 6 200 мА·год; дротове заряджання 80 Вт, 13,5 Вт PD, 55 Вт PPS, заряд до 100% за 53 хвилини, зворотне дротове заряджання.
- Комунікації: 5G; Wi-Fi 6; Bluetooth 5.4, aptX HD, LHDC 5; NFC; інфрачервоний порт.
- Додатково: Сканер відбитків пальців під дисплеєм (оптичний); стереодинаміки.
Зовні Reno15 Pro (mini) справляє враження майже ідеального компактного смартфона. Очікування стосувалися використання LTPO OLED-панелі, однак навіть без неї на рівні заявлених характеристик суттєвих зауважень не виникає.
Розпакування Oppo Reno15 Pro (mini)
Oppo Reno15 Pro (mini) постачається у великій сірій коробці, до якої входять сам смартфон, мережевий адаптер SuperVOOC потужністю 100 Вт, кабель USB-A – USB-C з допустимим струмом 8 А, а також інструмент для виймання SIM-картки.
У паперовому відсіку також знаходиться прозорий силіконовий чохол.
Дизайн, якість складання, ергономіка
Oppo Reno15 Pro (mini) має впізнаваний вигляд завдяки повністю пласкому дизайну, а компонування камер викликає асоціації з iPhone. Безумовно, компанія Apple не є автором ані такого підходу до дизайну, ані подібного розміщення модулів, проте саме вона зробила ці рішення масово впізнаваними, тому порівняння у цьому випадку є неминучим.
Конструктивно Reno15 Pro (mini) оснащено скляними панелями та пласкою алюмінієвою рамкою з матовим покриттям. Захист дисплея забезпечується склом Gorilla Glass 7i, тоді як тип захисного скла для матової задньої панелі виробником не уточнюється.
Reno15 Pro (mini) має сертифікацію IP68 та IP69, що означає захист від пилу, води та струменів води під високим тиском. Про наявність додаткових рішень для підвищення стійкості до падінь офіційно не повідомляється.
Reno15 Pro (mini) пропонується у кольорах Dusk Brown, Aurora Blue та Glacier White, причому останній доступний виключно для компактної версії. У розпорядженні для огляду перебувала версія Dusk Brown, яка за відтінком нагадує темно-сірий, близький до space gray, а також була можливість ознайомитися з білим варіантом.
Коричнева версія має повністю матове покриття як рамки, так і задньої панелі, завдяки чому поверхня відчувається шовковистою та менш схильною до появи відбитків пальців. Водночас смартфон залишається доволі слизьким у користуванні.
Білий варіант відрізняється глянцевою задньою панеллю та матовою рамкою. Дизайн виглядає більш експериментальним завдяки вбудованій блискучій декоративній смузі всередині заднього скла, при цьому рамка має не чисто білий, а радше сріблясто-золотистий відтінок. Саме ця версія забезпечує кращий хват, що пояснюється фізичними властивостями поверхонь, оскільки шорстке матове покриття створює меншу площу контакту, ніж повністю пласка глянцева поверхня.

Незалежно від вибору між більш чіпкою білою або більш слизькою коричневою версією, завдяки компактним габаритам та малій масі пристрій відчувається достатньо надійно та комфортно в руці. У разі потреби додаткову впевненість під час використання забезпечує захисний чохол, що входить до комплекту постачання.
Далі доцільно детальніше розглянути конструктивні елементи Reno15 Pro (mini).
Передня панель повністю відведена під 6,32-дюймовий AMOLED-дисплей. Матриця характеризується щільністю 460 ppi, частотою оновлення 120 Гц, 10-бітною глибиною кольору та надзвичайно тонкими рамками.
У верхній частині екрана розміщено невеликий виріз для фронтальної камери з роздільною здатністю 50 МП та автофокусом.
Над дисплеєм розташований майже непомітний розмовний динамік, який разом із додатковим верхнім отвором працює як частина стереосистеми.
Reno15 Pro (mini) оснащено оптичним сканером відбитків пальців, інтегрованим під дисплей. Сенсор активний навіть при вимкненому екрані, працює швидко та забезпечує високу точність і надійність розпізнавання.
Задня панель є повністю пласкою та містить знайомий за формою модуль камер. Конструкція виконана без розривів, оскільки блок камер є частиною задньої панелі, утворюючи єдиний цілісний елемент.
Компонування камер подібне до моделей iPhone 16 Pro, з трикутним розташуванням модулів та світлодіодним спалахом у верхньому правому куті. Лазерного LiDAR-сенсора у цій моделі не передбачено.
Бічні грані Reno15 Pro (mini) також пласкі, завдяки чому смартфон може самостійно стояти у вертикальному положенні.
На верхньому торці розміщено інфрачервоний порт, один мікрофон та додатковий отвір верхнього динаміка.
Нижня грань містить другий стереодинамік, порт USB-C, слот для двох SIM-карток, а також основний мікрофон.
Кнопки регулювання гучності та живлення або блокування розташовані на правому боці корпусу, мають достатній розмір та хід, що забезпечує чітке тактильне натискання.
Габарити Oppo Reno15 Pro (mini) становлять 151,2 x 72,4 x 8 мм, що приблизно відповідає розмірам iPhone 17 Pro. При цьому маса пристрою складає 187 г, що приблизно на 20 г менше, і це є доволі вражаючим показником.
Reno15 Pro (mini) поруч із Reno15
Загалом Oppo Reno15 Pro (mini) справляє враження дуже якісно зібраного смартфона з преміальним, хоч і знайомим дизайном, достатнім рівнем зчеплення, малою масою та габаритами, які роблять пристрій зручним для повсякденного використання.
Дисплей
Oppo Reno15 Pro (mini) оснащено 6,32-дюймовим AMOLED-дисплеєм із роздільною здатністю 1 216 x 2 640 пікселів, 10-бітною глибиною кольору, частотою оновлення 120 Гц та підтримкою стандарту HDR10+. Захист екрана забезпечується склом Gorilla Glass 7i.
Компанія Oppo заявляє типову яскравість на рівні 600 ніт та пікову яскравість до 1 800 ніт.
Під час вимірювань було зафіксовано максимальну ручну яскравість 602 ніт, що повністю відповідає заявленим виробником показникам. Мінімальна яскравість на білому тлі склала 2,1 ніт.
Для умов яскравого зовнішнього освітлення передбачено режим підвищеної яскравості. У більшості сценаріїв було зафіксовано значення 1 237 ніт, за винятком галереї, де автоматична яскравість підвищувалася до 2 214 ніт.
Пікову яскравість було протестовано з 10-відсотковим заповненням екрана, і результат виявився ще більш вражаючим, досягнувши рівня 3 548 ніт. Слід зазначити, що такий показник можливий виключно в мультимедійних застосунках, зокрема під час перегляду фотографій або потокового відео.
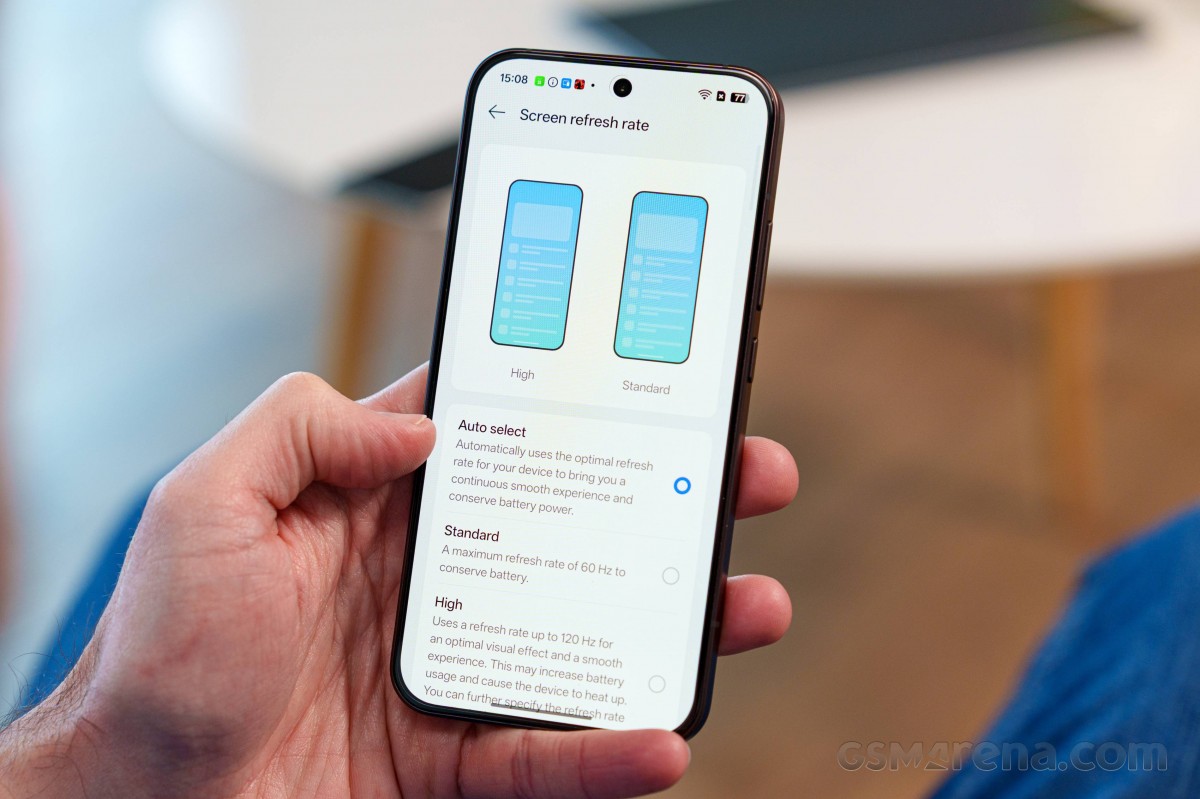
Частота оновлення
У налаштуваннях дисплея Reno15 Pro (mini) доступні три режими частоти оновлення, а саме Auto, Standard із фіксованими 60 Гц та High.
Режими Auto та High працюють однаково. Частота 60 Гц використовується для статичного екрана та відтворення відео, 90 Гц застосовується у веббраузері та системних застосунках, 60 Гц використовується для Netflix, YouTube, камери та низки інших програм, тоді як 120 Гц активується для інтерфейсу, ігор та бенчмарків.
Після вибору режиму High відкривається меню індивідуального налаштування частоти оновлення для окремих застосунків, у якому можна примусово встановити вищу частоту, ніж обрану автоматично, за умови підтримки з боку конкретного застосунку. Наприклад, можливо встановити 120 Гц для Chrome або 90 Гц чи 120 Гц для Netflix.
HDR та потокове відео
Екран підтримує стандарти HDR10 та HDR10+, і ці можливості коректно розпізнаються всіма основними потоковими сервісами, включно з Netflix.
Очікувано, Reno15 Pro (mini) підтримує стандарт Android Ultra HDR для відображення HDR-фотографій із покращеним тональним відображенням та підвищеною яскравістю світлих ділянок. Реалізація доступна у фірмовій галереї Oppo Photos, де для кожного окремого зображення можна тимчасово вимкнути ефект для порівняння, а також повністю деактивувати його у налаштуваннях системи. Підтримка також працює у Google Photos, хоча без можливості швидкого попереднього перегляду, а також у браузері Chrome для зображень з інших сумісних смартфонів.
Покращення зображення
У налаштуваннях дисплея Reno15 Pro (mini) доступні три додаткові опції, що заслуговують на увагу.
Функція Image Sharpener підвищує різкість зображень та відео низької якості, тоді як Video Color Boost розширює колірний обхват відео за можливості. Обидві функції призводять до підвищеного споживання енергії та можуть бути активовані лише у сумісних застосунках, більшість з яких орієнтовані на китайський ринок.
Швидкість заряджання
Oppo Reno15 Pro підтримує дротове заряджання SuperVOOC потужністю до 80 Вт, а також стандарт USB Power Delivery потужністю до 55 Вт. У комплекті постачання був присутній фірмовий зарядний пристрій Oppo SuperVOOC на 80 Вт, хоча на окремих ринках його наявність може відрізнятися, і саме він використовувався для тестування швидкості заряджання.
У смартфоні доступна функція Smart Rapid Charging, яка підвищує швидкість заряджання, водночас призводячи до дещо вищого нагрівання корпусу. Для досягнення максимально можливої потужності заряджання цю функцію було залишено активною.
Швидкість заряджання оцінюється як дуже висока, особливо з урахуванням ємності акумулятора 6 200 мА·год. Повний цикл заряджання із використанням адаптера на 80 Вт тривав 54 хвилини. За 15 хвилин заряджання рівень заряду досягав 36 відсотків, а за 30 хвилин — 62 відсотків. Показники виглядають переконливо, хоча на ринку присутні моделі з ще вищою швидкістю заряджання.
Підтримується режим bypass charging, який буде корисним під час ігор, оскільки дозволяє уникнути надмірного нагрівання пристрою та зниження продуктивності.
Функції розумного заряджання та обмеження рівня заряду рекомендуються для користувачів, які прагнуть продовжити загальний термін служби акумулятора.
Динаміки, гучність та якість звуку
Oppo Reno15 Pro (mini) оснащено стереодинаміками, при цьому розмовний динамік виконує подвійну функцію. В операційній системі передбачено додатковий рівень гучності, що перевищує стандартний максимум і позначається як 300%. Цей режим забезпечує незначне збільшення гучності за рахунок погіршення якості звуку, що проявляється у різкості високих частот та менш виразній передачі вокалу.
Під час тестування гучності Reno15 Pro (mini) отримав оцінку Very Good як при 300-відсотковому, так і при 100-відсотковому рівні гучності, при цьому у таблицях нижче наводиться показник LFS для режиму 300%. З огляду на погіршення якості звуку при використанні підсилення, тестові аудіодоріжки було записано на рівні гучності 100%.
Якість звучання динаміків на 100% гучності оцінюється як відмінна, із достатньою кількістю низьких частот, чіткою передачею вокалу та насиченим, але контрольованим високочастотним діапазоном. Звук є глибоким і об’ємним, що сприймається як суттєва перевага пристрою.
Android 16 з оболонкою ColorOS 16
Oppo Reno15 Pro (mini) постачається з попередньо встановленою оболонкою ColorOS 16, яка працює поверх операційної системи Android 16. Компанія Oppo заявляє, що нова серія Reno15 отримуватиме оновлення ColorOS протягом п’яти років, при цьому формулювання не уточнює точну кількість основних версій системи, а також гарантує шість років оновлень безпеки.
Актуальна версія ColorOS не демонструє кардинальних змін у порівнянні з попереднім випуском, проте містить низку доповнень, окремі візуальні та функціональні вдосконалення, а також значний набір можливостей на основі штучного інтелекту. Базові принципи інтерфейсу залишилися здебільшого незмінними, за винятком незначного оновлення дизайну окремих іконок.
Серед нових елементів цього року варто відзначити розширений вибір стилів годинника для екрана блокування, які використовують популярний ефект псевдотривимірної глибини, коли годинник частково ховається за елементами зображення, аналогічно до реалізації в iOS. Також значну увагу приділено анімаціям, кількість і плавність яких помітно зросли.
У меню застосунків з’явився новий стиль групування за категоріями, який нагадує підхід, реалізований іншими виробниками. Також підтримуються різні формати великих папок, зокрема з сіткою 1×3, 3×1 та 3×3. Функція Smart Sidebar збережена і доступна для швидкого доступу до обраних інструментів.
На борту присутній широкий набір інструментів штучного інтелекту від Google, включно з асистентом Gemini, сервісом Gemini Live, функцією Circle to Search, перекладом тексту на екрані та іншими можливостями. Окремо відзначається інтеграція Gemini із застосунком Oppo Mind Space.
Окрім рішень від Google, доступний також великий набір фірмових AI-функцій Oppo. Функція AI Speak призначена для озвучування текстів, AI Writer допомагає зі створенням текстового контенту, AI Search здійснює пошук інформації у підтримуваних застосунках на смартфоні, AI Translate забезпечує переклад, а AI VoiceScribe використовується для створення підсумків текстів або зображень.
У системі також присутній застосунок AI Studio, який використовує хмарні генеративні алгоритми для створення фотореалістичних зображень або анімацій у різних стилях на основі фотографії користувача. Використання сервісу не є необмеженим, однак при першій реєстрації надається певна кількість кредитів, які згодом можна поповнювати шляхом регулярного використання застосунку.
У галереї доступні інструменти редагування фотографій на основі штучного інтелекту. Серед них AI Eraser, AI Ultra Clarity та AI Unblur, призначення яких є інтуїтивно зрозумілим. До нових функцій також належать AI Recompose, AI Relight для корекції експозиції на портретах та AI Perfect Shot, що дозволяє виправляти закриті очі на знімках.
Продуктивність та бенчмарки
Oppo Reno15 Pro (mini) працює на базі процесора MediaTek Dimensity 8450, виготовленого за 4-нм техпроцесом. Це незначне оновлення порівняно з Dimensity 8400, яке зосереджене на оптимізаціях для ігор завдяки рушію StarSpeed Engine, покращеній роботі камер через оновлений ISP, а також більш енергоефективній моделі енергозбереження Ultra Save 3.0+. Архітектура центрального та графічного процесорів при цьому залишилася без змін.
Чипсет оснащений восьмиядерним процесором із конфігурацією 1×3,25 ГГц Cortex-A725, 3×3,0 ГГц Cortex-A725 та 4×2,1 ГГц Cortex-A725. За графіку відповідає прискорювач Mali-G720 MC7.
Reno15 Pro (mini) доступний у двох конфігураціях пам’яті з накопичувачем стандарту UFS 3.1 та оперативною пам’яттю LPDDR5X, а саме 12 ГБ оперативної пам’яті з 256 ГБ сховища, що використовувалася для тестування, та 12 ГБ оперативної пам’яті з 512 ГБ сховища.
Далі наведено результати тестування у синтетичних бенчмарках.
Dimensity 8450 демонструє значний потенціал у своєму ціновому сегменті та забезпечує продуктивність, близьку до флагманського рівня. Хоча центральний та графічний процесори не є найпотужнішими на ринку, їхні показники залишаються серед найвищих у своєму класі.
Втім, тривала продуктивність Reno15 Pro (mini) оцінюється як посередня. Чи є це наслідком компактного корпусу, чи недостатньо ефективної системи відведення тепла, достеменно встановити неможливо, однак така поведінка є типовою для компактних смартфонів. У тестах на стабільність Reno15 Pro (mini) утримував приблизно 66 відсотків від максимальної продуктивності центрального процесора та лише близько 35 відсотків від пікової продуктивності графічного процесора.
Під час тривалих стрес-тестів Reno15 Pro (mini) помітно нагрівається, однак не досягає рівня, який можна було б охарактеризувати як надмірний.
Використання потужного чипсета у Reno15 Pro (mini) забезпечує високий рівень загальної продуктивності. За час експлуатації не було зафіксовано жодних затримок або збоїв у роботі інтерфейсу, іграх чи звичайних застосунках. Водночас, з огляду на суттєве зниження графічної продуктивності під навантаженням, у тривалих ігрових сесіях можливі обмеження продуктивності.
Повнофункціональна потрійна тилова камера, надширокі селфі
Лінійка Oppo Reno15 може справляти враження хаотичної з огляду на назви та сегментацію, однак принаймні серед уже анонсованих моделей простежується чітка закономірність: якщо в назві присутній індекс Pro, пристрій отримує потрійну основну камеру з конфігурацією 200 МП + 50 МП + 50 МП. Такий набір виглядає переконливо.
Основна камера Reno15 Pro (mini), що розглядається, побудована на сенсорі Samsung HP5. Цей модуль фактично стає стандартним вибором для більш якісних смартфонів середнього класу поточного покоління. Фізичний розмір сенсора відповідає попереднім моделям Reno цього сегмента, однак замість роздільної здатності 50 МП тут використовується 200 МП. Камера оснащена об’єктивом з еквівалентною фокусною відстанню 24 мм, світлосилою f/1.8 та оптичною стабілізацією зображення.
Телефотокамера забезпечує 3,5-кратне оптичне наближення з еквівалентною фокусною відстанню 85 мм. Судячи з характеристик, модуль перейшов із попередніх поколінь. Використовується сенсор Samsung JN5 на 50 МП. Це не надто складне рішення з погляду апаратної частини, але для більшості сценаріїв воно є достатнім. Для зйомки крупних планів камера підходить гірше через мінімальну дистанцію фокусування 32 см.
Надширококутна камера також має роздільну здатність 50 МП, проте використовує менш поширений сенсор GalaxyCore. Характеристики виглядають цілком гідно: оптичний формат 1/2.88 дюйма, об’єктив з еквівалентною фокусною відстанню 16 мм та наявність автофокусу.
На фронтальній панелі встановлено ще один сенсор JN5, який орієнтований на селфі високої роздільної здатності. Окрім цього, камера оснащена надширококутним об’єктивом з еквівалентною фокусною відстанню 18 мм, що замінює вже доволі широкий 21 мм у попередніх поколіннях Reno. Також передбачено автофокус.
- Ширококутна (основна): 200 МП Samsung ISOCELL HP5 (S5KHP5, 1/1.56″, 0.5 мкм–2.0 мкм); 24 мм, f/1.8, OIS, багатонапрямлений PDAF (10 см – ∞); запис відео 4K60.
- Телефото: 50 МП Samsung ISOCELL JN5 (S5KJN5, 1/2.76″, 0.64 мкм–1.28 мкм); 85 мм, f/2.8, OIS, багатонапрямлений PDAF (32 см – ∞); 4K60.
- Надширококутна: 50 МП GalaxyCore GC50F6 (1/2.88″, 0.61 мкм–1.22 мкм); 16 мм, f/2.0, PDAF; 4K60.
- Фронтальна камера: 50 МП Samsung ISOCELL JN5 (S5KJN5, 1/2.76″, 0.64 мкм–1.28 мкм); 18 мм, f/2.0, багатонапрямлений PDAF; 4K60.
Якість фото при денному освітленні
Основна камера
Основна камера Reno15 Pro (mini) забезпечує дуже хороші результати за умов яскравого денного освітлення. Знімки відзначаються широким динамічним діапазоном та точною автоматичною передачею балансу білого з приємною кольоропередачею. Рівень деталізації загалом високий, хоча дрібні високочастотні текстури виглядають надмірно обробленими та перешарпленими.
Режим High resolution, який формує зображення роздільною здатністю 26 МП, виявився працездатним лише для дуже обмеженого набору сцен, переважно з наявністю рослинності, причому не для всіх подібних сюжетів. Цікавим є те, що він стабільно спрацьовував в одному конкретному сюжеті за різних умов освітлення. Трава та гілки на таких знімках виглядають помітно краще, однак відсутність можливості примусово активувати режим 26 МП або принаймні отримати візуальну індикацію в видошукачі робить використання цього режиму непередбачуваним.
Під час зйомки в режимі Hi-res через селектор режимів, а не через налаштування High resolution у меню форматів, за замовчуванням створюються 200-мегапіксельні знімки без можливості вибору проміжного варіанту 50 МП. Водночас смартфон автоматично переходить на 50 МП у режимі Hi-res при зниженні освітленості нижче певного порогу. Така поведінка виглядає нестабільною та малопрактичною.
Самі 200-мегапіксельні зображення сприймаються неоднозначно через дуже великі розміри файлів та посередній рівень деталізації.
Знімки людей при масштабі 1x виходять відмінними. Відтінки шкіри виглядають природно, деталізація облич є реалістичною. Рівень розмиття в портретному режимі за замовчуванням може здаватися дещо надмірним.
При 2-кратному цифровому збільшенні зображення виглядають трохи м’якими. Враховуючи використання 200-мегапіксельного сенсора, очікування були вищими, тим більше що на інших смартфонах із цим самим сенсором вдавалося отримати кращі результати. Якість не є поганою, однак потенціал використано не повністю.
Для портретної зйомки така м’якість не створює проблеми. Портрети при 2x виглядають дуже привабливо, з оптимальним балансом між деталізацією та більш компліментарною перспективою.
Телефотокамера
Телефотокамера Reno15 Pro демонструє дуже хорошу якість при 3,5-кратному зумі. Динамічний діапазон широкий, баланс білого коректний, насиченість кольорів підібрана вдало. Рівень деталізації високий, хоча й не максимально можливий. Доволі велика мінімальна дистанція фокусування у поєднанні з дещо м’якими результатами на цій відстані є певним недоліком.
Можлива зйомка 50-мегапіксельних кадрів із 3,5-кратним зумом, однак виграшу в деталізації це не дає, обмежуючись збільшенням розміру файлів.
Портрети з 3,5-кратним зумом виглядають відмінно. Перспектива та компресія, характерні для цієї фокусної відстані, забезпечують дуже привабливий результат. Відтінки шкіри передаються коректно, а стандартний рівень боке в портретному режимі тут значно краще відповідає фокусній відстані, ніж на менших значеннях зуму.
Кнопка 7,5x також дозволяє отримувати прийнятні результати. Окремі деталі можуть виглядати надмірно перешарпленими, однак загальна різкість і деталізація залишаються на гідному рівні разом із відмінними глобальними параметрами, характерними для нативного зуму.
Надширококутна камера
Фотографії з надширококутної камери майже відповідають рівню флагманських пристроїв. Різкість і деталізація високі, динамічний діапазон широкий, кольори добре відкалібровані.
Використання режиму повної роздільної здатності не дає помітних переваг, оскільки ці зображення фактично є масштабованими версіями стандартних кадрів.
Селфі
Reno15 Pro оснащений дуже цікавим модулем для селфі, який поєднує популярний 50-мегапіксельний сенсор із незвично широким об’єктивом. Нативна фокусна відстань 18 мм дозволяє захоплювати значно більше простору або знімати групові селфі з великою кількістю людей. Якість зображень є відмінною. Відтінки шкіри передаються коректно, деталізація на рівні окремих пікселів висока. Наявність автофокусу забезпечує різкі знімки навіть з малої відстані.
Рівень масштабування 1x дає лише трохи м’якші результати, тому для тих, хто віддає перевагу просто широким, а не надшироким селфі, доступний повноцінний варіант із еквівалентною фокусною відстанню 25 мм. Знімки при 2x з близької відстані виглядають значно слабше.
Якість фото за слабкого освітлення
Основна камера
Основна камера Reno15 Pro демонструє хороші результати й у нічних умовах. Вихідні зображення не є найрізкішими серед усіх протестованих, оскільки флагманські моделі здатні передавати більше дрібних деталей та текстур, які тут виглядають згладженими. Водночас експозиція підібрана вдало, динамічний діапазон дуже широкий, можливо навіть надто широкий через дещо агресивне відновлення світлих ділянок, що однак не створює серйозних проблем. Автоматичний баланс білого стабільно працює за складних комбінацій вуличного освітлення, а кольори залишаються насиченими без переходу в крайнощі.
Телефотокамера
Якість знімків із телефотокамери є доброю, проте без встановлення нових стандартів. Деталізація достатня, хоча й не видатна. Динамічний діапазон також на хорошому рівні, баланс білого зазвичай точний, насиченість кольорів підібрана коректно, хоча іноді трапляються окремі кадри з вибіленими ділянками.
Режим 7-кратного зуму формує відносно м’які зображення, однак загальні параметри залишаються приємними, що робить його придатним у ситуаціях, де композиція важливіша за піксельну точність.
Надширококутна камера
Знімки з надширококутної камери не вирізняються особливими досягненнями, але й не розчаровують. Деталізація є достатньою для модуля цього класу, динамічний діапазон широкий. Баланс білого іноді може відхилятися, однак це не є критичним недоліком.
Вердикт щодо якості фотографій
Reno15 Pro є надійним смартфоном для фотозйомки, який забезпечує загалом відмінні денні результати з усіх трьох тилових камер. Користувач може розраховувати на широкий динамічний діапазон, приємну кольоропередачу та загалом добру деталізацію, хоча й трохи нижчу за ідеальну. Пристрій особливо добре проявляє себе в портретній зйомці. Якість нічних фото є стабільною без суттєвих недоліків на будь-якій з камер, хоча рівень деталізації дещо поступається очікуванням. Окремо варто відзначити універсальну фронтальну камеру з надширококутним об’єктивом та автофокусом, яка однаково добре підходить для групових знімків і крупних планів.
Якість відео
Reno15 Pro можна вважати доволі добре оснащеною відеокамерою. Смартфон підтримує запис відео з роздільною здатністю до 4K при 60 кадрах за секунду на всіх камерах, окрім стандартного режиму 4K30. Режим із частотою 24 кадри за секунду відсутній. Професійного відеорежиму не передбачено, проте є режим Movie, який обмежує зйомку роздільною здатністю 2340×1080 пікселів при 30 кадрах за секунду.
Доступний вибір між кодеками h.264 та h.265, причому ефективніший h.265 використовується за замовчуванням. Запис HDR-відео можливий у всіх режимах якості. Стабілізацію можна вмикати або вимикати, за замовчуванням вона вимкнена.
Характер зображення у відео відповідає загальній тенденції, притаманній Reno15 Pro. Динамічний діапазон і кольоропередача є відмінними, однак різкість і деталізація не завжди вражають. Основна камера та телефотомодуль забезпечують прийнятний рівень різкості, тоді як надширококутна камера формує занадто м’яке зображення.
У нічних умовах ситуація залишається подібною. Відео при 1x та 3,5x виглядає достатньо впевнено, тоді як матеріал із надширококутної камери залишається м’яким.
Стабілізація працює дуже надійно. Під час ходьби тремтіння ефективно згладжується, зйомка з нерухомого положення дає стабільні кадри, а панорамування виглядає плавним.
Вердикт щодо якості відео
Можливість запису відео у форматі 4K60 на всіх камерах Reno15 Pro є суттєвою перевагою. Додатково доступний HDR у всіх режимах та майже бездоганна стабілізація. Кольори й динамічний діапазон виглядають відмінно як удень, так і вночі. Деталізація є прийнятною на основній камері та телефотомодулі, проте залишається нижчою за бажану на надширококутній камері.
Висновок
Ринок загалом, і цей ціновий сегмент зокрема, зовсім не перенасичений компактними смартфонами. Ситуація є радше протилежною. Саме цей дефіцит безпосередньо працює на користь Reno15 Pro (mini), дозволяючи йому легко виділятися серед небагатьох альтернатив.
Насамперед пристрій пропонує знайомий за стилістикою, але якісно реалізований дизайн, у центрі якого перебуває міцна конструкція корпусу та вдало підібрані варіанти кольорового оформлення. Дисплей також справляє сильне враження. Він є чітким і яскравим, забезпечує плавну анімацію та насичену передачу кольорів, а також підтримує HDR10+ у всіх потокових сервісах, які використовувалися під час тестування.
Попри компактні габарити, Reno15 Pro (mini) оснащений несподівано ємним акумулятором, який забезпечує відмінну автономність при роботі від одного заряду. У поєднанні з достатньо швидкою дротовою зарядкою та вражаючими стереодинаміками загальний набір характеристик виглядає добре збалансованим.
Окремо варто відзначити систему камер, яка виявилася однією з ключових переваг смартфона. Усі чотири камери, включно з фронтальною, стабільно забезпечують відмінну якість фотографій упродовж дня. Якість відеозйомки відповідає цьому рівню, а майже бездоганна стабілізація працює надійно та послідовно на всіх модулях.
На завершення слід зазначити, що Reno15 Pro (mini) оснащений дійсно швидким процесором, хоча стабільна продуктивність під тривалим навантаженням не є його сильною стороною. Пікова продуктивність помітно знижується при тривалому навантаженні на центральний або графічний процесор, що є типовою поведінкою для компактних пристроїв, які розглядалися раніше. Водночас варто враховувати, що подібні екстремальні сценарії малоймовірні у повсякденному використанні.
У підсумку Reno15 Pro (mini) майже в усьому демонструє правильний баланс характеристик. Відносно компактні розміри поєднуються з відмінним дисплеєм, вражаючою автономністю, високою якістю камер та гідними динаміками. За відсутності обмежень зі стабільною продуктивністю під навантаженням пристрій можна було б вважати майже бездоганним, однак навіть у поточному вигляді він повністю заслуговує на дуже високу рекомендацію.
Переваги
- Високоякісний дизайн і відмінна якість збірки.
- Яскравий OLED-дисплей з підтримкою HDR10+ та частотою оновлення 120 Гц.
- Видатна автономність і швидка зарядка.
- Фотографії та відео флагманського рівня з усіх чотирьох камер, включно з автофокусом на надширококутній.
- Надзвичайно ефективна стабілізація відео.
- Інфрачервоний порт та підтримка eSIM.
Недоліки
- Суттєве зниження продуктивності під високим і тривалим навантаженням.
За матеріалами: GSMArena
The post Огляд Oppo Reno15 Pro: потрапляє майже в кожне “яблучко” appeared first on .


















 Reno15 Pro (mini) поруч із Reno15
Reno15 Pro (mini) поруч із Reno15